

1. 컬렉션 프레임워크(Collections Framework)
☾ 컬렉션 프레임워크(Collections Framework)
: 컬렉션(다수의 객체)을 다루기 위한 표준화된 프로그래밍 방식
: 인터페이스와 다형성을 이용한 객체지향적 설계를 통해 표준화
: java.util 패키지에 포함(jdk1.2부터 제공)
컬렉션 프레임워크의 핵심 인터페이스

- Collection (컬렉션)
: 컬렉션을 다루는데 가장 기본적인 메서드 정의(읽고, 추가하고, 삭제)

List (리스트)
: 순서 O, 중복 O 데이터의 집합(ex. 대기자 명단)
- 구현클래스 : ArrayList, LinkedList, Stack, Vector 등

Set (집합)
: 순서 X, 중복 X 데이터의 집합(ex. 양의 정수 집합)
- 구현클래스 : HashSet, TreeSet 등


Map (맵)
: 키(key)와 값(value)의 쌍으로 이루어진 데이터의 집합(ex. 아이디와 패스워드)
: 순서 X, 키 중복 X, 값 중복 O
- 구현클래스 : HashMap, TreeMap, Hashtable, Properties 등

2. ArrayList
☾ ArrayList
: List 인터페이스를 구현(순차 저장, 중복 허용)
: 기존의 Vector를 개선한 것으로 구현원리와 기능적으로 동일
: 데이터의 저장공간으로 배열 사용
: 가장 많이 사용됨
| 기능 | 설명 | 작성 예시 | 결과 |
| add | 추가 | arrList.add("사과"); | {"사과"} |
| get | 가져오기 | arrList.get(0); | "사과" |
| set | 수정 | arrList.set(0, "바나나"); | {"바나나"} |
| contains | 포함 여부 | arrList.contains("바나나"); | true |
| remove | 삭제 | arrList.remove("바나나"); | { } |
| clear | 전체 삭제 | arrList.clear(); | { } |
- 장점
: 구조 간단하고 데이터를 읽는 시간(접근시간) 짧음
- 단점
: 크기를 변경할 수 없음(데이터 복사, 메모리 낭비)
: 비순차적인 데이터의 추가, 삭제에 많은 시간 걸림
import java.util.*;
public class ArrayListEx1 {
public static void main(String[] args) {
ArrayList<Integer> list1 = new ArrayList<>(10);
list1.add(new Integer(5));
list1.add(new Integer(4));
list1.add(new Integer(2));
list1.add(new Integer(0));
list1.add(new Integer(1));
list1.add(new Integer(3));
ArrayList list2 = new ArrayList(list1.subList(1, 4));
print(list1, list2);
Collections.sort(list1);
Collections.sort(list2);
print(list1, list2);
System.out.println("list1.containsAll(list2):"+list1.containsAll(list2));
list2.add("B");
list2.add("C");
list2.add(3, "A");
print(list1, list2);
list2.set(3, "AA");
print(list1, list2);
// list1에서 list2와 겹피는 부분만 남기고 나머지는 삭제
System.out.println("list1.retainAll(list2):"+list1.retainAll(list2));
print(list1, list2);
// list2에서 list1에 포함된 객체들 삭제
for (int i = list2.size()-1; i >= 0; i--) {
if (list1.contains(list2.get(i))) {
list2.remove(i);
}
}
print(list1, list2);
}
static void print(ArrayList list1, ArrayList list2) {
System.out.println("list1:"+list1);
System.out.println("list2:"+list2);
System.out.println();
}
}list1:[5, 4, 2, 0, 1, 3]
list2:[4, 2, 0]
list1:[0, 1, 2, 3, 4, 5]
list2:[0, 2, 4]
list1.containsAll(list2):true
list1:[0, 1, 2, 3, 4, 5]
list2:[0, 2, 4, A, B, C]
list1:[0, 1, 2, 3, 4, 5]
list2:[0, 2, 4, AA, B, C]
list1.retainAll(list2):true
list1:[0, 2, 4]
list2:[0, 2, 4, AA, B, C]
list1:[0, 2, 4]
list2:[AA, B, C]
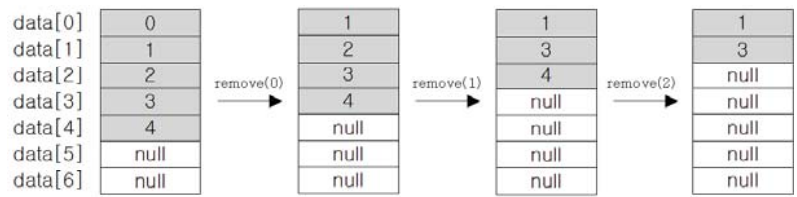
ArrayList에 저장된 객체의 삭제 과정

- 삭제할 데이터 아래의 데이터를 한 칸씩 위로 복사해서 삭제할 데이터를 덮어씀(마지막 데이터의 경우 이 과정 필요 없음)
- 데이터가 모두 한 칸씩 이동했으므로 마지막 데이터는 null로 변경
- 데이터가 삭제되어 데이터의 개수가 줄었으므로 size의 값 감소
① 첫 번째 객체부터 삭제하는 경우(배열 복사 발생)
for (int i = 0; i < list.size(); i++) {
list.remove(i);
}
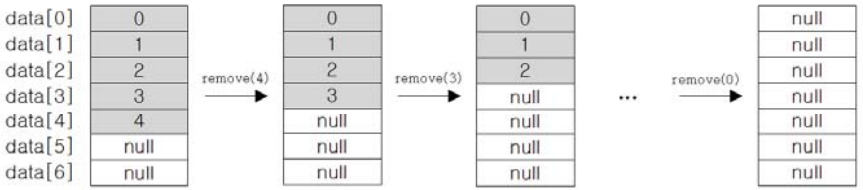
② 마지막 객체부터 삭제하는 경우(배열 복사 발생 안함)
for (int i = list.size()-1; i >= 0; i--) {
list.remove(i);
}
Vector
// 1. 용량(capacity)이 5인 Vector 생성
Vector v = new Vector(5);
v.add("1");
v.add("2");
v.add("3");
// 2. 빈 공간 제거(용량 == 크기)
v.trimToSize();
// 3. 용량 6 이상 되도록 함
v.ensureCapacity(6);
// 4. 크기 7이 되게 함
v.setSize(7);
// 5. Vector에 저장된 모든 요소 제거
v.clear();

3. LinkedList
☾ LinkedList
: 불연속적으로 존재하는 데이터를 서로 연결
: 배열의 단점 보완
: 데이터의 빠른 삽입, 삭제 가능
LinkedList<String> list = new LinkedList<>();
list.add("사과");
list.add("바나나");
for (String s:list) {
System.out.println(s);
}| 기능 | 설명 | 작성 예시 | 결과 |
| add | 추가 | lList.add("사과"); | {"사과"} |
| get | 가져오기 | lList.get(0); | "사과" |
| addFirst | 맨 앞에 추가 | lList.addFirst("바나나"); | {"바나나", "사과"} |
| addLast | 맨 뒤에 추가 | lList.addLast("딸기"); | {"바나나", "사과", "딸기"} |
| getFirst | 처음 요소 가져오기 | lList.getFirst(); | "바나나" |
| getLast | 마지막 요소 가져오기 | lList.getLast(); | "딸기" |
| clear | 전체 삭제 | lList.clear(); | { } |
- 데이터의 삭제 : 단 한 번의 참조 변경만으로 가능

- 데이터의 추가 : 한 번의 Node 객체 생성과 두 번의 참조 변경만으로 가능

종류
- Linked list (링크드 리스트) : 연결리스트. 데이터 접근성이 나쁨
class Node {
Node next;
Object obj;
}
- Doubly linked list (더블리 링크드 리스트) : 이중 연결리스트. 접근성 향상
class Node {
Node next;
Node previous;
Object obj;
}
- Doubly circular linked list (더블리 써큘러 링크드 리스트) : 이중 원형 연결리스트

ArrayList vs LinkedList
- 순차적으로 데이터 추가 / 삭제 : ArrayList가 빠름
- 비순차적으로 데이터 추가 / 삭제 : LinkedList가 빠름
- 접근 시간(access time) : ArrayList가 빠름
4. Stack & Queue
☾ Stack (스택)
: LIFO(Last In First Out)
: 마지막에 저장된 데이터를 가장 먼저 꺼냄
ex. 수식 계산, 수식 괄호 검사, undo/redo, 뒤로/앞으로

☾ Queue(큐)
: FIFO(First In First Out)
: 처음에 저장된 데이터를 가장 먼저 꺼냄
ex. 최근 사용문서, 인쇄 작업 대기 목록, 버퍼(buffer)

import java.util.*;
public class StackQueueEx {
public static void main(String[] args) {
Stack st = new Stack();
Queue q = new LinkedList();
st.push("0");
st.push("1");
st.push("2");
q.offer("0");
q.offer("1");
q.offer("2");
System.out.println("= Stack =");
while (!st.empty()) {
System.out.println(st.pop());
}
System.out.println("= Queue =");
while (!q.isEmpty()) {
System.out.println(q.poll());
}
}
}= Stack =
2
1
0
= Queue =
0
1
2
Queue의 변형
- Deque (덱)
: Stack과 Queue의 결합. 양 끝에서 저장(offer)과 삭제(poll) 가능
- 구현 클래스 : ArrayDeque, LinkedList

- PriorityQueue (우선순위 큐)
: 우선순위가 높은 것부터 꺼냄(null 저장 불가)
: 입력[3,1,5,2,4] -> 출력 [1,2,3,4,5]
- BlockingQueue (블락킹 큐)
: 비어 있을 때 꺼내기와 가득 차 있을 때 넣기를 지정된 시간 동안 지연시킴(멀티쓰레드)
5. Iterator & ListIterator & Enumeration
: 컬렉션에 저장된 데이터를 접근하는데 사용되는 인터페이스
: Enumeration은 Iterator의 구버전
☾ Iterator
: 컬렉션의 모든 데이터를 순차적으로 조회
: 컬렉션에 iterator()를 호출해서 Iterator를 구현한 객체를 얻어 사용
import java.util.*;
public class IteratorEx1 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("1");
list.add("2");
list.add("3");
list.add("4");
list.add("5");
Iterator it = list.iterator();
while (it.hasNext()) { // 다음 요소가 있는지 확인
Object obj = it.next(); // 다음 요소 가져오기
System.out.print(obj);
}
}
}12345
☾ ListIterator
: Iterator에서 양방향 조회 기능 추가(단방향 -> 양방향)
: listIterator()를 통해 얻음
: List를 구현한 컬렉션 클래스에 존재
import java.util.*;
public class ListIteratorEx1 {
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add("1");
list.add("2");
list.add("3");
list.add("4");
list.add("5");
ListIterator it = list.listIterator();
while (it.hasNext()) {
System.out.print(it.next());
}
System.out.println();
while (it.hasPrevious()) {
System.out.print(it.previous());
}
System.out.println();
}
}12345
54321
6. Arrays
☾ Arrays
: 배열을 다루는데 유용한 메서드 제공
- 배열의 복사
- copyOf() : 배열 전체 복사
- copyOfRange() : 배열의 일부 복사라여 새로운 배열 만들어 반환
- 배열 채우기
- fill() : 배열의 모든 요소를 지정된 값으로 채움
- setAll() : 배열을 채우는데 사용할 함수형 인터페이스를 매개변수로 받음
- 배열의 정렬과 검색
- sort() : 배열 정렬
- binarySearch() : 배열의 저장된 요소를 검색. 반드시 정렬된 상태여야 작동
- 배열의 비교와 출력
- equals() : 배열의 두 배열에 저장된 모든 요소를 비교(다차원 배열에서는 deepEquals())
- toString() : 배열의 모든 요소를 문자열로 출력(다차원 배열에서는 deepToString())
- 배열을 List로 변환
- asList(Object... a) : 배열을 List에 담아서 반환
7. Comparator & Comparable
: 객체를 정렬하는데 필요한 메서드를 정의한 인터페이스
: 정렬 기준을 제공
- compare(), compareTo() : 두 객체의 비교 결과를 반환하도록 작성
- Comparator : 기본 정렬 기준 외에 다른 기준으로 정렬하고자 할 때 사용
- Caomparable : 기본 정렬 기준을 구현하는데 사용
import java.util.*;
public class ComparatorEx {
public static void main(String[] args) {
String[] strArr = {"cat", "Dog", "lion", "tiger"};
Arrays.sort(strArr); // String의 Comparable 구현에 의한 정렬
System.out.println("strArr="+Arrays.toString(strArr));
Arrays.sort(strArr, String.CASE_INSENSITIVE_ORDER); // 대소문자 구분 안함
System.out.println("strArr="+Arrays.toString(strArr));
Arrays.sort(strArr, new Descending()); // 역순정렬
System.out.println("strArr="+Arrays.toString(strArr));
}
}
class Descending implements Comparator {
public int compare(Object o1, Object o2) {
if (o1 instanceof Comparable && o2 instanceof Comparable) {
Comparable c1 = (Comparable)o1;
Comparable c2 = (Comparable)o2;
return c1.compareTo(c2)*(-1);
}
return -1;
}
}strArr=[Dog, cat, lion, tiger]
strArr=[cat, Dog, lion, tiger]
strArr=[tiger, lion, cat, Dog]
8. HashSet
☾ HashSet
: Set 인터페이스를 구현한 대표적인 컬렉션 클래스
: 순서, 중복 허용 X
: 순서를 유지하려면 LinkedHashSet 클래스 사용
HashSet<String> set = new HashSet<>();
set.add("사과"); // {"사과"}
set.add("바나나"); // {"사과", "바니나"}
set.add("사과"); // {"사과", "바니나"} 중복 허용 X
9. TreeSet
☾ TreeSet
: 이진 검색 트리(binary search tree)로 구현
: Set 인터페이스를 구현
: 범위 검색과 정렬에 유리한 컬렉션 클래스
: 이진 검색 트리는 부모보다 작은 값을 왼쪽에, 큰 값은 오른쪽에 저장
: HashSet보다 데이터 추가, 삭제에 시간 더 걸림

10. HashMap
☾ HashMap
: Map 인터페이스를 구현한 대표적인 컬렉션 클래스
: (Key, Value) 자료구조
: 순서, 중복 허용 X
: 순서를 유지하려면 LinkedHashMap 클래스 사용
: 해싱(hashing) 기법으로 데이터 저장
HashMap<String, Integer> map = new HashMap<>();
map.put("사과", 10);
map.put("바나나", 20);| 기능 | 설명 | 작성 예시 | 결과 |
| put | 추가 | map.put("사과", 10); | {"사과":10} |
| get | 가져오기 | map.get("사과"); | 10 |
| containsKey | Key 포함 여부 | map.contains("딸기"); | false |
| remove | 삭제 | map.remove("사과"); | { } |
| clear | 전체 삭제 | map.clear(); | { } |
- hashing (해싱)
: 해시함수(hash function)로 해시 테이블에 데이터를 저장, 검색
: 해시 테이블은 배열과 링크드 리스트가 조합된 형태

11. TreeMap
☾ TreeMap
: 범위 검색과 정렬에 유리한 컬렉션 클래스
: Map 인터페이스를 구현
: 이진 검색 트리의 구조로 키와 값의 쌍으로 이루어진 데이터 저장
: HashMap보다 데이터 추가, 삭제에 시간 더 걸림
12. Properties
☾ Properties
: HashMap의 구버전인 Hashtable을 상속 받아 구현
: 키와 값을 (Object, Object)의 형태로 저장
: 주로 어플리케이션의 환경설정에 관련된 속성 저장
13. Collections
☾ Collections
: 컬렉션을 위한 메서드(static) 제공
- 컬렉션 채우기, 복사, 정렬, 검색 - fill(), copy(), sort(), binarySearch()
- 컬렉션의 동기화 - synchronizedXXX()
- 변경 불가(readOnly) 컬렉션 만들기 - unmodifiableXXX()
- 싱글톤 컬렉션 만들기 - singletonXXX()
- 한 종류의 객체만 저장하는 컬렉션 만들기 - checkedXXX()
요약
| ArrayList | 배열 기반. 데이터의 추가와 삭제에 불리. 순차적인 추가/삭제는 제일 빠름. 임의의 요소에 대한 접근성 뛰어남 |
| LinkedList | 연결 기반. 데이터의 추가와 삭제에 유리. 임의의 요소에 대한 접근성 나쁨 |
| Stack | Vector를 상속받아 구현(LIFO) |
| Queue | LinkedList가 Queue 인터페이스 구현(FIFO) |
| HashSet | HashMap을 이용하여 구현 |
| TreeSet | TreeMap을 이용하여 구현 |
| HashMap | 배열 + 연결. 추가, 삭제, 검색, 접근성 모두 뛰어남. 검색에서 최고 성능 |
| TreeMap | 연결 기반. 정렬과 검색(범위검색)에 적합. 검색 성능은 HashMap보다 나쁨 |
| LinkedHashMap LinkedHashSet |
HashMap과 HashSet에 저장 순서 유지 기능 추가 |
| Properties | Hashtable을 상속받아 구현 |

'Back-end > JAVA' 카테고리의 다른 글
| [JAVA] JDK & IntelliJ 버전 변경(Windows) (0) | 2024.01.05 |
|---|---|
| [JAVA] 지네릭스(Generics), 열거형(enums), 어노테이션(Annotation) (1) | 2023.10.28 |
| [JAVA] 날짜와 시간 & 형식화 (1) | 2023.10.14 |
| [JAVA] java.lang 패키지와 유용한 클래스 - Object, String, Math, wrapper 클래스 (0) | 2023.10.07 |
| [JAVA] 예외처리 - try-catch문, 예외 선언, 예외 되던지기 (0) | 2023.09.23 |