

순환 신경망(Recurrent Neural Network, RNN)
- 여러 개의 데이터가 순서대로 입력되었을 때 앞서 입력받은 데이터를 잠시 기억해 놓는 방법
- 기억된 데이터가 얼마나 중요한지 판단하고 별도의 가중치를 주어 다음 데이터로 넘김
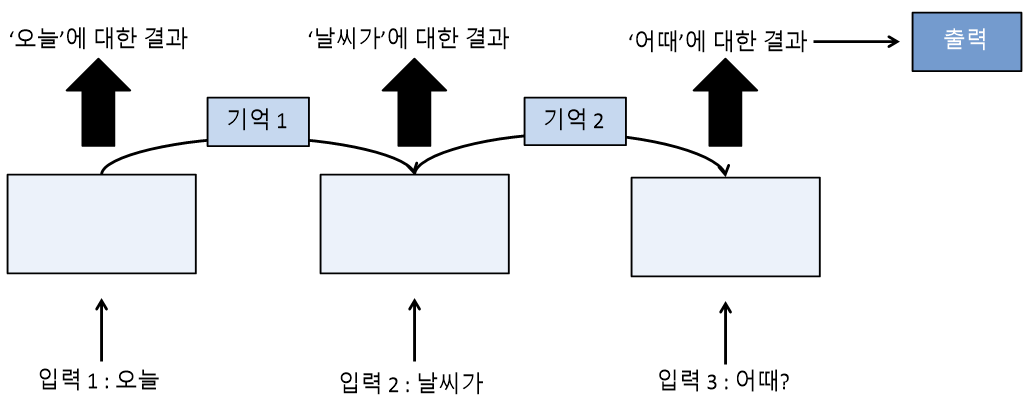
1. 다수 입력 단일 출력
ex) 문장을 읽고 뜻을 파악할 때
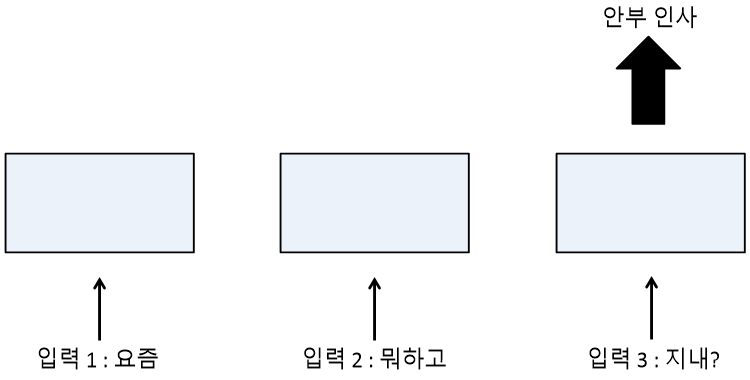
2. 단일 입력 다수 출력
ex) 사진의 캡션을 만들 때

3. 다수 입력 다수 출력
ex) 문장을 번역할 때

LSTM(Long Short Term Memory)
- 반복되기 전에 다음 층으로 기억된 값을 넘길지 여부를 관리하는 단계를 하나 더 추가
- RNN의 기울기 소실 문제를 보완

LSTM 예제 - 로이터 뉴스 카테고리 분류 데이터
- 11,228개의 뉴스 기사를 읽고 이 데이터가 어떤 의미를 지니는지 46개의 카테고리로 분류
1. 환경 및 데이터 준비
- load_data(num_words=n, test_split=n)
: 데이터셋 로드
- num_words : 가장 빈도가 높은 상위 단어의 개수
- test_split : 테스트셋으로 지정할 데이터 비율
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Embedding
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.datasets import reuters # 로이터 뉴스 데이터셋 불러오기
from tensorflow.keras.callbacks import EarlyStopping
import numpy as np
import matplotlib.pyplot as plt
# 데이터를 불러와 학습셋, 테스트셋으로 나눔
(X_train, y_train), (X_test, y_test) = reuters.load_data(num_words=1000, test_split=0.2)
2. 데이터 확인
- 로이터 뉴스 데이터는 토큰화와 정수 인코딩 완료된 상태
category = len(set(y_train))
print('카테고리 :', category)
print('학습용 뉴스 기사 :', len(X_train))
print('테스트용 뉴스 기사 :', len(X_test))
print(X_train[0])카테고리 : 46
학습용 뉴스 기사 : 8982
테스트용 뉴스 기사 : 2246
[1, 2, 2, 8, 43, 10, 447, 5, 25, 207, 270, 5, 2, 111, 16, 369, 186, 90, 67, 7, 89, 5,
19, 102, 6, 19, 124, 15, 90, 67, 84, 22, 482, 26, 7, 48, 4, 49, 8, 864, 39, 209, 154,
6, 151, 6, 83, 11, 15, 22, 155, 11, 15, 7, 48, 9, 2, 2, 504, 6, 258, 6, 272, 11, 15,
22, 134, 44, 11, 15, 16, 8, 197, 2, 90, 67, 52, 29, 209, 30, 32, 132, 6, 109, 15, 17, 12]
3. 데이터 전처리 - 패딩(padding), 원-핫 인코딩
- 패딩
- maxlen : 단어 수 맞춤
# 단어의 수 맞추어 줌
X_train = sequence.pad_sequences(X_train, maxlen=100)
X_test = sequence.pad_sequences(X_test, maxlen=100)
- 원-핫 인코딩
# 원-핫 인코딩 처리
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
4. 모델 설정
- LSTM()
: LSTM 층 생성
: keras에 존재
- activation: LSTM의 활성화 함수로는 주로 tanh 함수 사용
model = Sequential()
model.add(Embedding(1000, 100))
model.add(LSTM(100, activation='tanh'))
model.add(Dense(46, activation='softmax'))
5. 모델 실행 환경 설정 및 최적화
# 모델의 실행 옵션 결정
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 학습의 조기 중단 설정
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5)
6. 모델 실행
history = model.fit(X_train, y_train, batch_size=20, epochs=200, validation_data=(X_test, y_test), callbacks=[early_stopping_callback])
# 테스트 정확도 출력
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, y_test)[1]))
6. 데이터 시각화
# 학습셋과 테스트셋의 오차 저장
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
# 그래프로 표현
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
# 그래프에 그리드를 주고 레이블 표시
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
'모두의 딥러닝 개정 3판'의 내용과 https://github.com/taehojo/deeplearning의 코드 참고
'AI > 모두의 딥러닝' 카테고리의 다른 글
| [모두의 딥러닝] 23. 텍스트 전처리 - 원-핫 인코딩(one-hot encoding), 단어 임베딩(word embedding), 긍정 부정 예측 (0) | 2023.06.03 |
|---|---|
| [모두의 딥러닝] 22. 텍스트 전처리 - 토큰화(tokenization), 빈도 수 세기 (0) | 2023.06.02 |
| [모두의 딥러닝] 21. 컨볼루션 신경망(CNN), 풀링(Pooling), 드롭아웃(drop out), 플래튼(flatten) - MNIST 데이터 (0) | 2023.06.02 |
| [모두의 딥러닝] 20. 이미지 인식, 데이터 전처리 - MNIST 데이터 (2) | 2023.05.29 |
| [모두의 딥러닝] 19. 결측치 처리, 속성별 관련도 추출 - 부동산 가격 예측 데이터 (0) | 2023.05.29 |